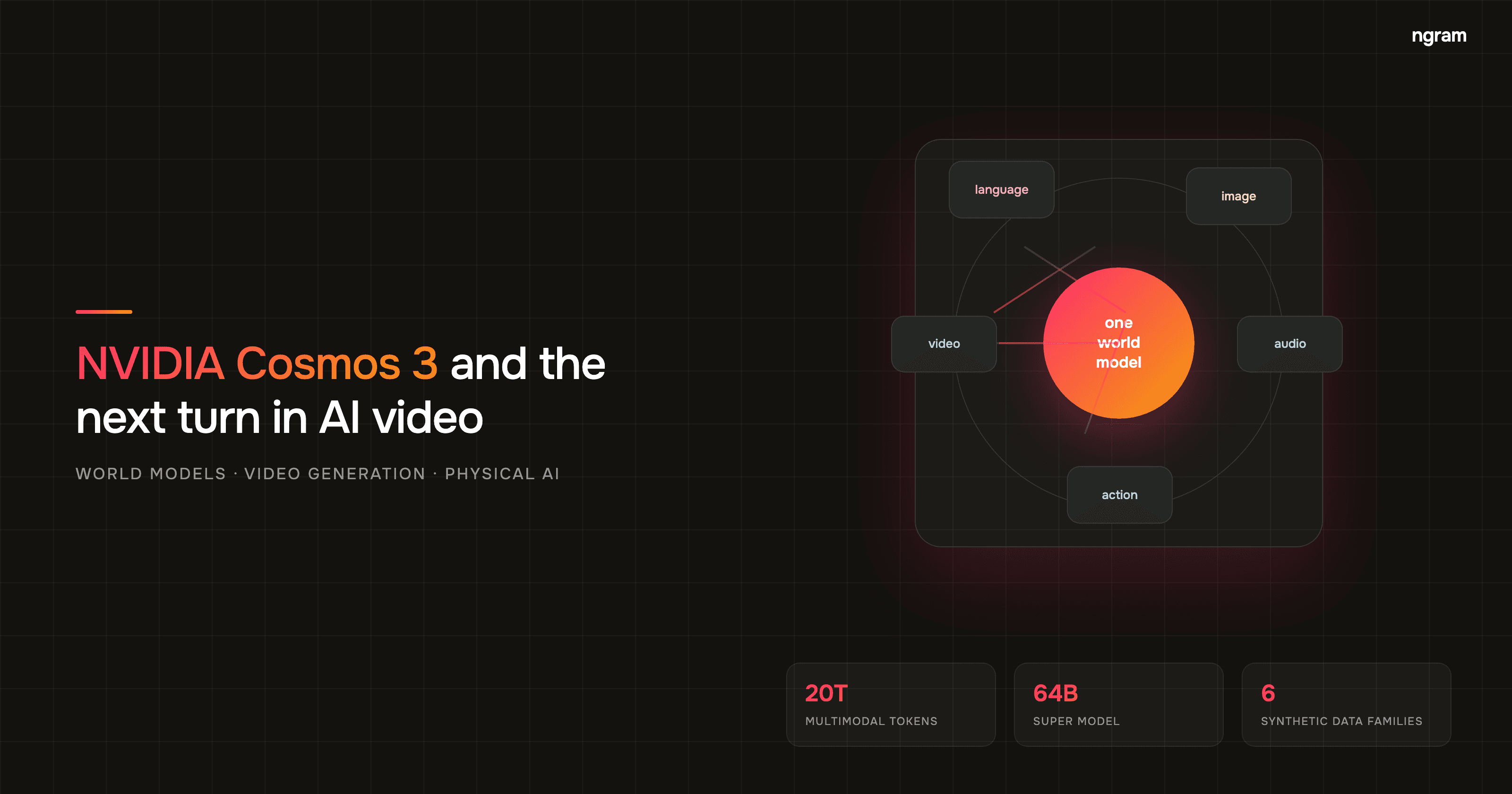
NVIDIA Cosmos 3 landed on June 1, 2026, and the headline looks like robotics news at first glance. NVIDIA describes it as an open world foundation model for physical AI, built for robots, autonomous vehicles, warehouse systems, and other machines that need to understand the real world before acting in it.
But the release also says something important about AI video. The next serious leap is not only prettier clips. It is video models that understand motion, causality, spatial layout, future states, and the action that produced a scene.
That is why this release belongs in the AI video conversation. Cosmos 3 connects text, images, video, audio, and action inside a shared model, according to NVIDIA's Cosmos Lab page. That makes it less like a standard text-to-video tool and more like a simulation layer that can generate, reason, and plan.
NVIDIA Cosmos 3 Is a Video Model That Plans Before It Generates
Most AI video generation still starts with a surface-level brief: prompt in, clip out. That is useful, but it is also why many generated clips break when the scene has weight, contact, timing, object permanence, or human motion.
Cosmos 3 approaches the problem differently. NVIDIA says the model uses a Mixture-of-Transformers architecture with two paired towers: a reasoner tower that reads multimodal inputs and a generator tower that produces future observations and action sequences. The company describes the reasoner as the part that interprets motion, object interaction, and physical context before generation happens in its technical blog.
The key phrase is "before generation happens." For AI video, that is the difference between drawing a plausible frame sequence and modeling the world that frame sequence is supposed to show.
What NVIDIA Actually Released
The June 1 release is more than a research paper. NVIDIA announced Cosmos 3 Super and Cosmos 3 Nano, with Cosmos 3 Edge coming soon, according to the official press release. The same announcement says the models can natively understand and generate text, images, video, ambient sound, and actions.
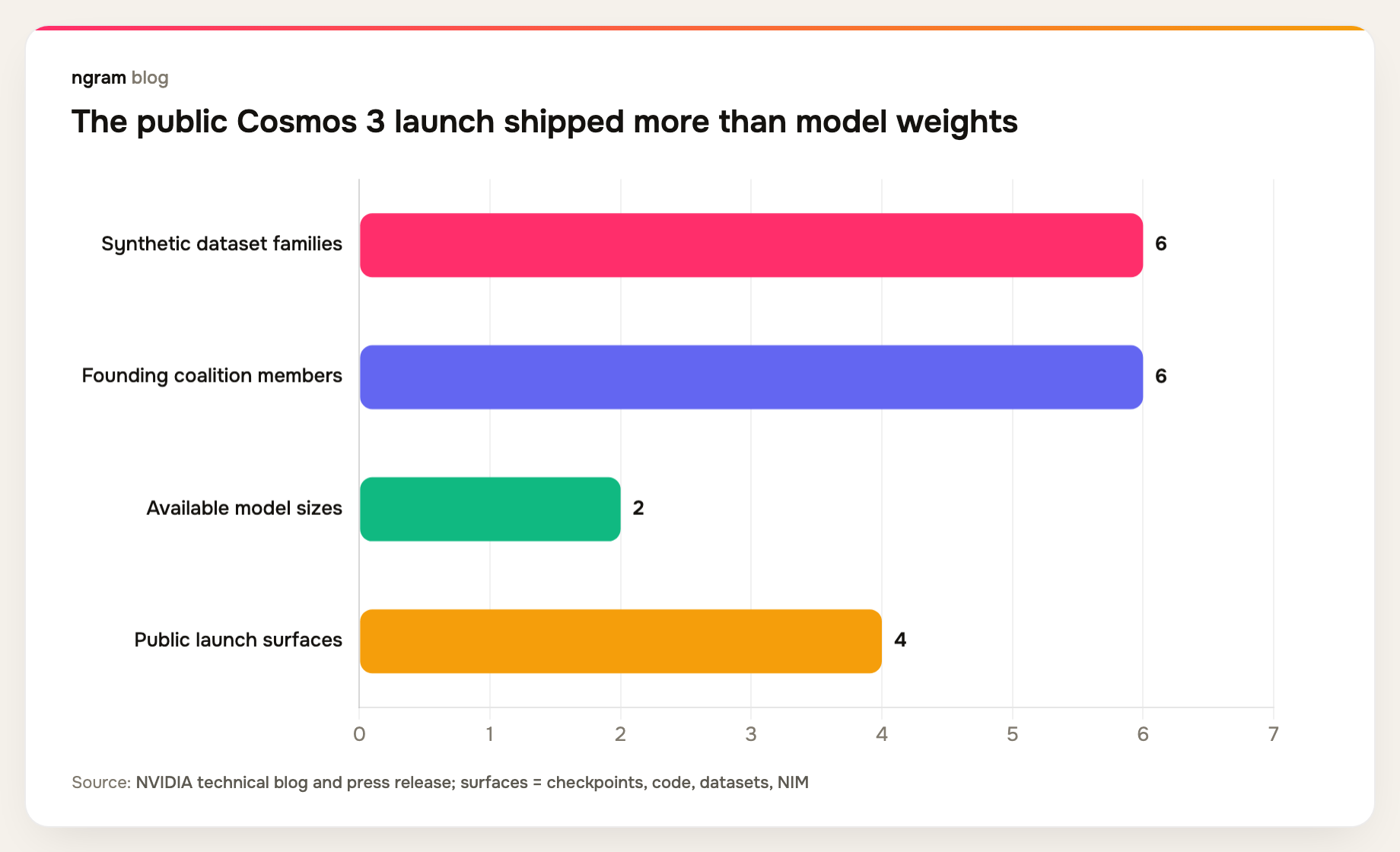
The public package also includes model checkpoints on Hugging Face, code on GitHub, six synthetic data generation dataset families, post-training scripts, and NVIDIA NIM microservices. In other words, this is not a demo video with a waitlist. It is infrastructure that physical AI teams can inspect, adapt, and deploy.
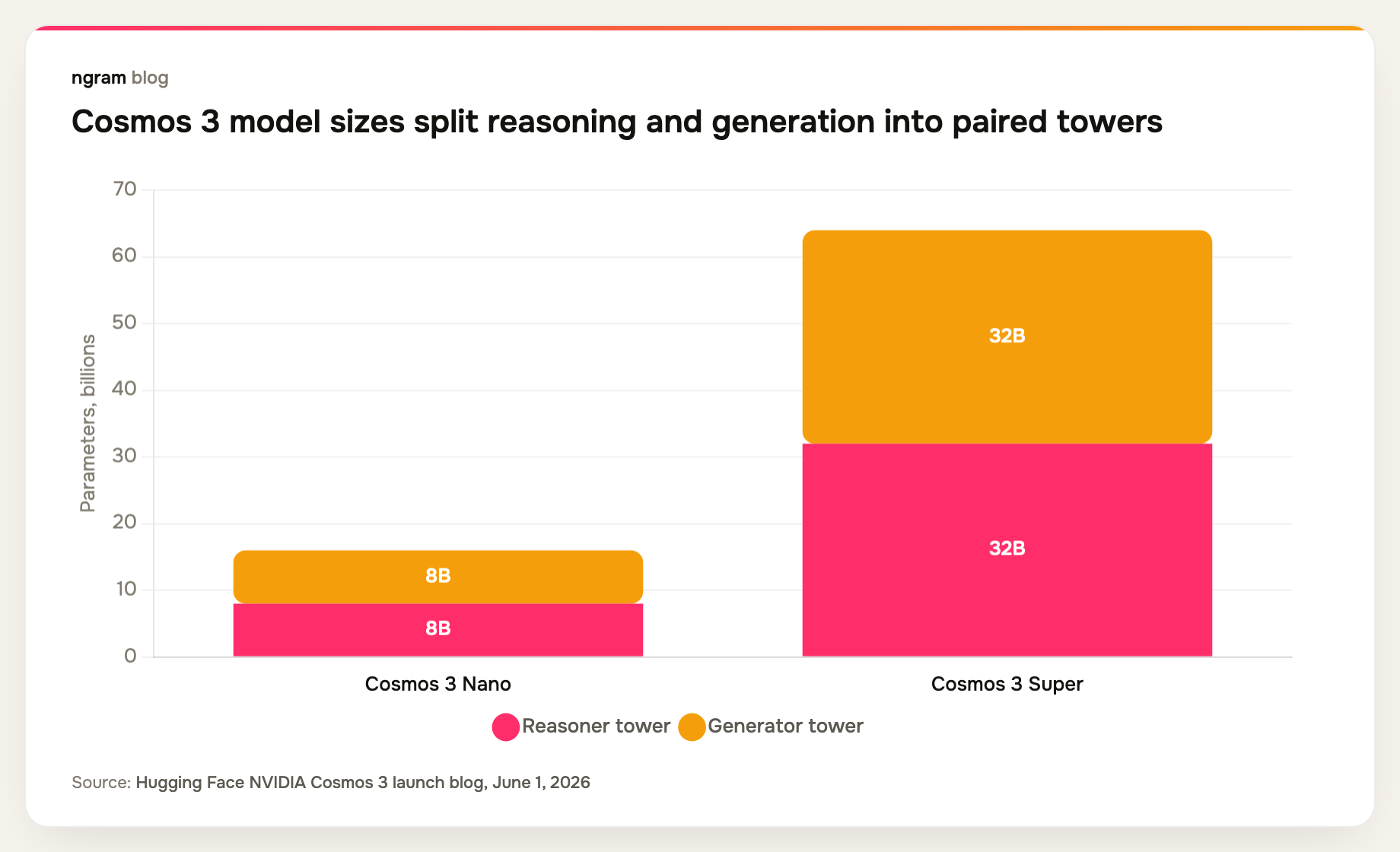
- Two model sizes are available now: Cosmos 3 Nano at 16B parameters and Cosmos 3 Super at 64B parameters.
- Six synthetic dataset families cover robotics, physics simulation, spatial reasoning, human motion, autonomous driving, and warehouse operations.
- The Cosmos Coalition includes Agile Robots, Black Forest Labs, Generalist, LTX, Runway, and Skild AI as founding members named by NVIDIA.
- The reasoner NIM is available now, while NVIDIA says the generator NIM is still to come.
The Scale Is Big, But the Training Mix Is the Story
Axios reported that NVIDIA trained Cosmos 3 on 20 trillion multimodal tokens, including nearly one billion images and 400 million real and synthetic videos. The important detail is not only the size. It is the mix: images, videos, ambient audio, text, and action data from humans and robots.
That action data changes the job. A normal AI video generator can produce what a scene looks like. A world model needs to estimate how a scene changes, why it changes, and what a system should do next. Axios quotes NVIDIA's Ming-Yu Liu saying that action data is what separates Cosmos from a regular video generator.
This is also where the arXiv paper is useful. The Cosmos 3 abstract says the model subsumes vision-language models, video generators, world simulators, and world-action models into one framework. That is the strategic claim: video is not the output category anymore. Video is one interface into a model of the world.
Early Demand Is Already Visible on Hugging Face
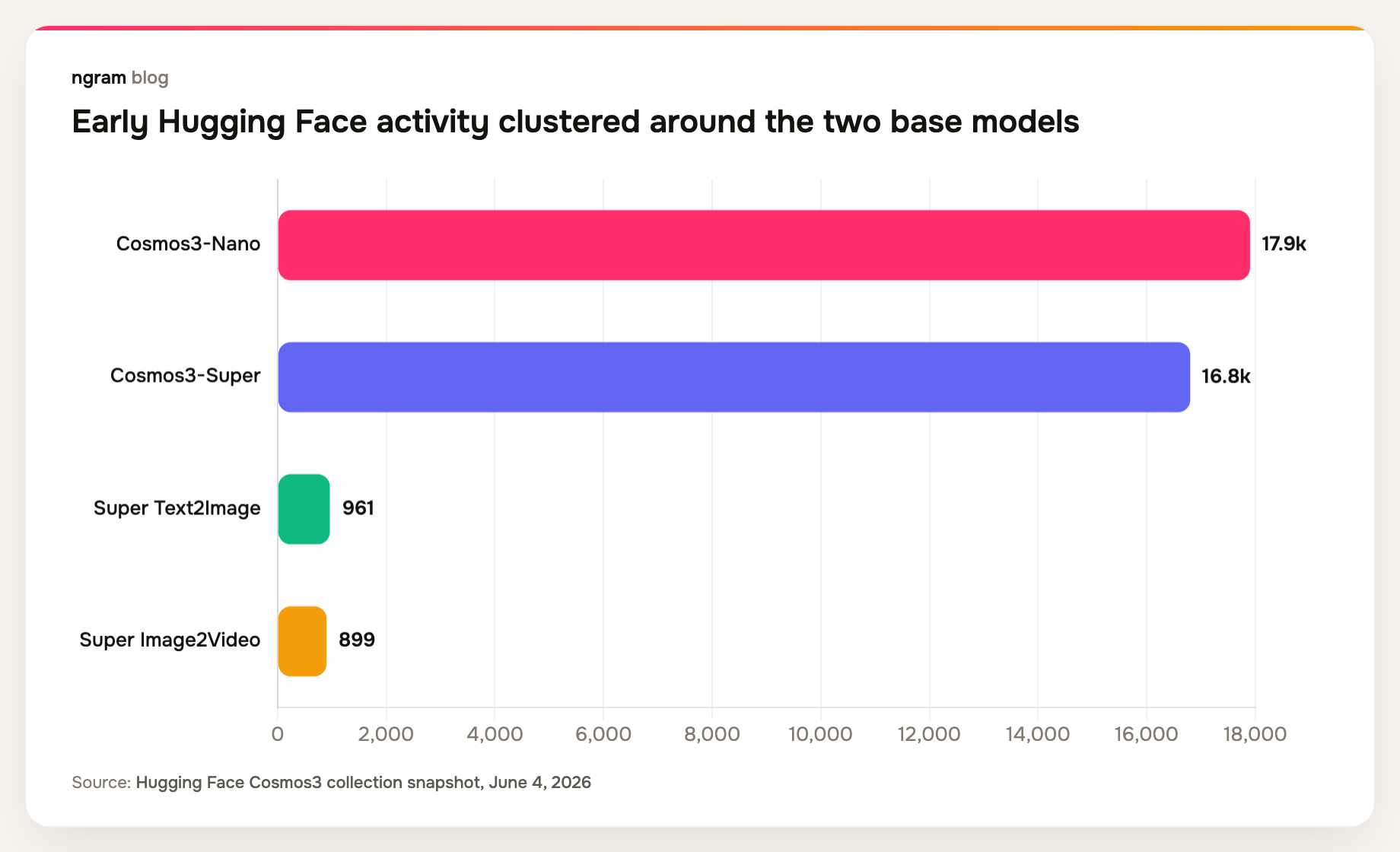
Because Cosmos 3 is openly distributed, there is a useful early signal in the model collection itself. On June 4, 2026, the Hugging Face Cosmos3 collection listed Cosmos3-Nano at 17.9k and Cosmos3-Super at 16.8k activity counts in the page snapshot, while the specialized Super Image2Video and Text2Image entries were still under 1k each.
Treat that as an early adoption snapshot, not a durable benchmark. It still tells us where attention went first: builders started with the base models, not only the specialized image-to-video AI variants.
Why NVIDIA Cosmos 3 Matters for AI Video Teams
Most business teams will not run Cosmos 3 directly this quarter. The compute profile is serious, the target user is technical, and NVIDIA's first use cases are physical AI, not marketing clips.
The impact still matters. Better world models tend to flow into the tools that non-technical teams use later. If a model can preserve object identity, reason about physical contact, and predict future states, the downstream AI video generator experience becomes less about rerolling prompts and more about controlling scenes.
That is especially relevant for image-to-video workflows. When a still image becomes motion, the hardest part is not movement itself. It is believable movement: hands that stay attached, products that do not morph, shadows that follow objects, and camera moves that keep geometry intact.
The same logic applies to text-to-video conversion. A stronger model should not only render a prompt. It should hold the intent of the prompt across time, which is what teams need when a clip supports a product demo, launch message, or training video.
That distinction matters for business-video workflows. Scripts and storyboards need to exist before rendering, and stronger video models feed that pipeline best when they respect the plan instead of forcing the user to chase random outputs.
What Cosmos 3 Does Not Mean
The easy mistake is to read Cosmos 3 as proof that every AI video editor will become autonomous overnight. That is not what NVIDIA shipped.
Cosmos 3 is aimed at builders of robots, AV systems, smart spaces, and synthetic data pipelines. It is open, but open does not mean simple. The 64B Super model targets data center deployment on NVIDIA Hopper and Blackwell GPUs, while Nano is the efficient 16B option for workstation-grade compute, according to the technical blog.
It also does not remove the need for editorial judgment. A model can simulate motion and still make the wrong communication choice. A polished business video still needs audience, message, pacing, captions, channel format, and brand control.
That is why the next phase of AI video creation for business probably looks like a stack: planning systems decide what the video should say, frontier models produce controlled scenes, editors refine the result, and provenance systems show what was generated.
The Practical Read: From Clip Generation to Scene Control
Cosmos 3 is important because it points at the problem that matters after novelty fades. People do not only want generated video. They want generated video that can be directed, revised, trusted, and connected to a real workflow.
For robotics, that means a model can preview action before a machine takes it. For business video, the equivalent is less dramatic but still valuable: a model that holds scene intent across frames, preserves objects, follows timing, and makes edits without rebuilding everything from scratch.
If you are evaluating AI video tools, watch for three questions in the months ahead:
- Can the tool preserve physical consistency across a full scene, not just a single impressive moment?
- Can the tool accept structured direction, such as a storyboard, reference image, product screenshot, or action sequence?
- Can the tool revise a scene without throwing away the whole take?
That is the useful lens. Cosmos 3 is not a consumer video app launch. It is a signal that AI video is being pulled toward controllable world modeling. The teams that benefit first will be the ones that treat generation as part of a planned workflow, not a slot machine.
If your team already has source material and needs a planned business video from it, try ngram. The useful question is not which model can make the flashiest clip. It is which workflow turns the message you have into a video people can understand.
Frequently Asked Questions
What is NVIDIA Cosmos 3?
NVIDIA Cosmos 3 is an open family of omnimodal world models for physical AI. It processes and generates across text, images, video, audio, and action, with a focus on reasoning about physical scenes and predicting what happens next.
Is Cosmos 3 an AI video generator?
Partly. Cosmos 3 can generate video, including image-to-video and text-to-video-style outputs, but NVIDIA positions it as a world model for physical AI. The bigger idea is simulation, reasoning, and action prediction, not only clip generation.
Why does Cosmos 3 matter for image to video AI?
Image to video AI gets better when models understand physical continuity. If a model can reason about spatial relationships, object states, and motion, it has a better chance of turning a still image into movement that feels coherent instead of random.
Can marketers use Cosmos 3 directly?
Most marketers will not use Cosmos 3 directly. It is more likely to influence the AI video stack through model providers, developer tools, and products that integrate better generation and control behind a simpler interface.
What is the difference between a video model and a world model?
A video model generates frames that look plausible over time. A world model tries to represent how a scene works, including objects, motion, cause and effect, and possible future states. Cosmos 3 is notable because it connects both jobs in one framework.
What should business teams watch after Cosmos 3?
Watch for tools that make AI video generation more controllable: storyboard-aware generation, better scene edits, stronger image-to-video consistency, and fewer full rerenders. Those changes matter more for production work than one-off visual demos.