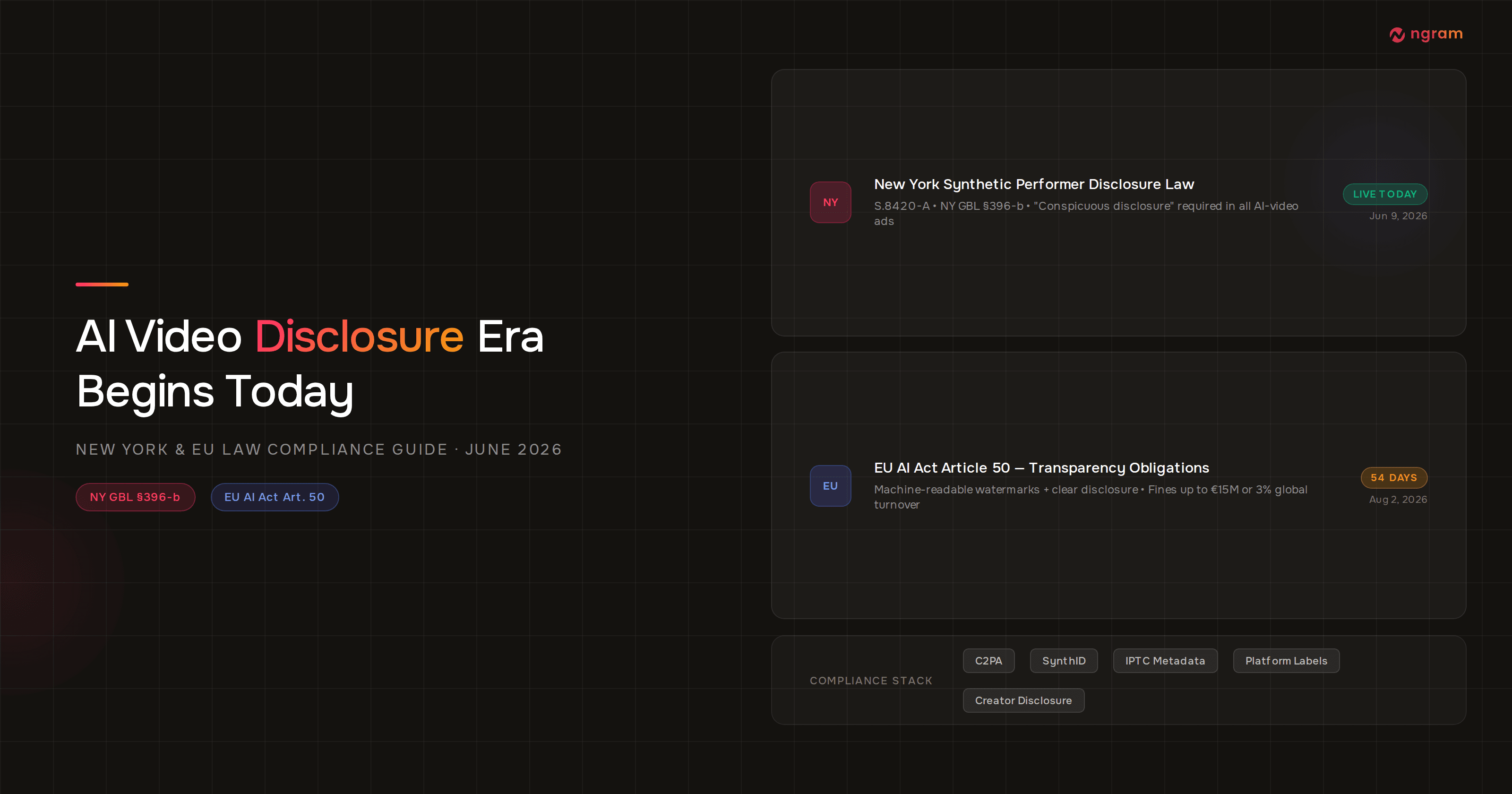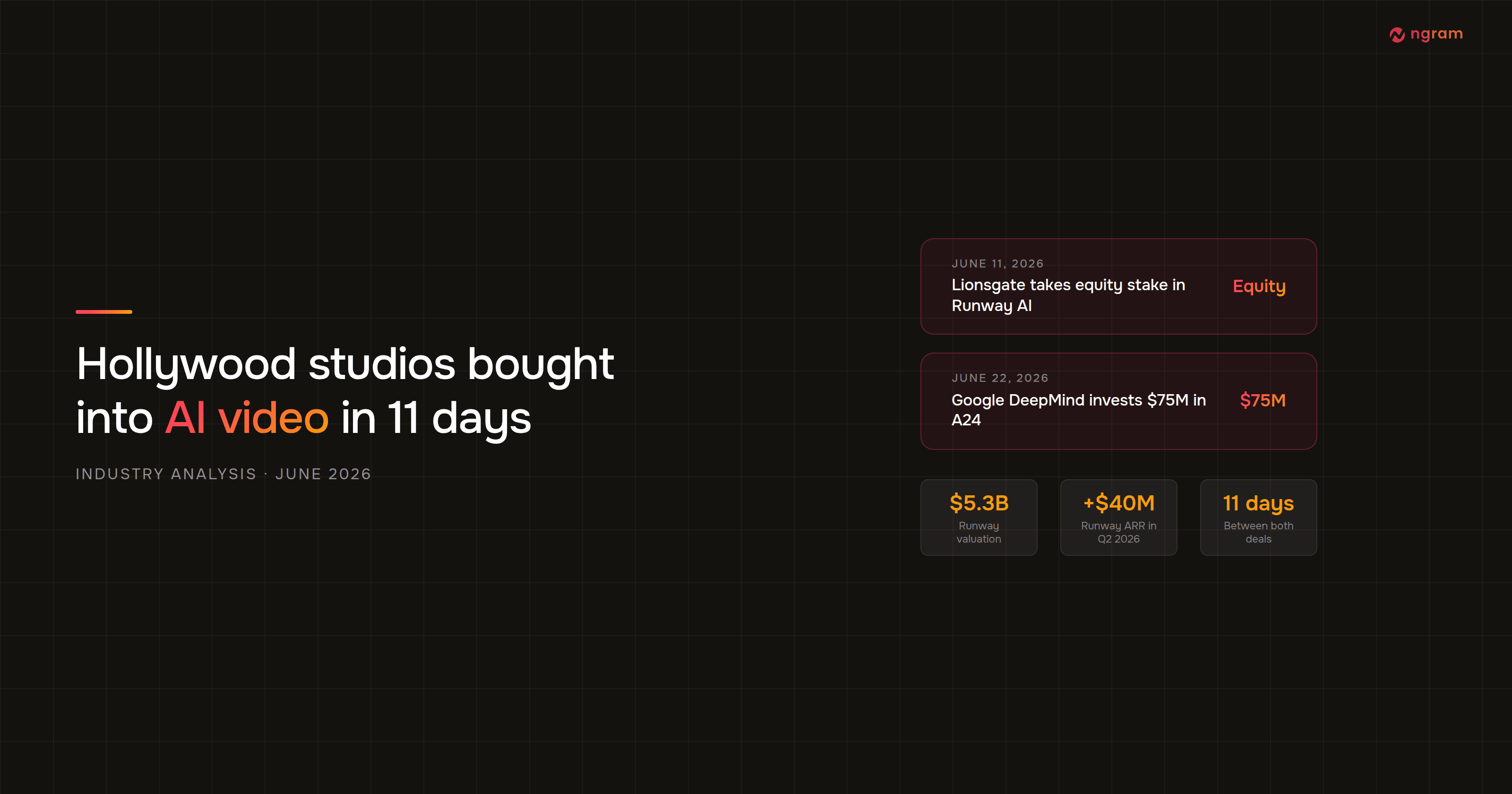
Avataar.ai launched Varya in New Delhi on June 12, 2026, with MeitY Secretary S Krishnan in the room and the IndiaAI Mission's backing on the announcement. The pitch: India's first indigenous, distilled video generation model, built for Indian cultural context and priced for Indian scale, according to Analytics India Magazine.
The sovereign-AI framing will get the headlines. The number that matters is the cost of AI video generation: Varya generates video at Rs 0.48 per second, about half a US cent, on Avataar's hosted service. TechCrunch puts that against models like Veo, Kling, Luma, and Runway, which typically charge $0.10 or more per second. That is roughly a 20x gap.
One company's price card is an anecdote. But Varya lands in a six-month stretch where Luma cut per-second pricing 3x, Google shipped a 5-cent Veo tier, and OpenAI scheduled Sora for shutdown. Read together, the AI video generation cost curve is not drifting down. It is collapsing, and the launch in New Delhi shows where the collapse leads: open weights, distilled inference, and state-subsidized compute.
What Avataar Actually Launched
Varya is a 14-billion-parameter video model that handles both text to video and image to video generation and can extend clips into longer sequences. Avataar did not train it from scratch. The team started with Wan 2.2, Alibaba's openly licensed video model, and used distillation to compress generation from 50 diffusion steps down to 4 while keeping output quality comparable, according to BusinessToday and Avataar's launch materials.
The launch package, drawn from TechCrunch, Analytics India Magazine, and Outlook Business:
- Hosted price of Rs 0.48 (about $0.005) per second of generated video, which Avataar's internal benchmarks describe as up to 10x more cost-efficient than leading global video models. Both figures are company claims.
- A 5-second 720p clip generates in about 45 seconds on a single NVIDIA H200 GPU. The Wan 2.2 base model takes 1,230 seconds for the same output, a 27x speedup.
- A planned open-weight release on AI Kosh, the Indian government's public AI repository, including the training data, so developers can self-host or modify the model.
- Training tuned to Indian cultural context: festivals, food, clothing, architecture, and everyday public spaces that global models trained on Western-heavy data tend to miss.
- Backing from Peak XV and Tiger Global, with more than $55 million raised since the company's 2014 founding, plus selection as one of roughly 12 startups in the IndiaAI Mission's foundation-model program.
Avataar CEO Sravanth Aluru put the strategy in one line at the launch event: "For a country of 1.4 billion people, affordability is not a feature, it is a prerequisite," as quoted by Analytics India Magazine.
A caveat worth keeping. The 10x cost-efficiency figure and the quality-parity claim both come from Avataar's own benchmarks, published before the weights are public. The company says a technical report on architecture and methodology is coming. Until third parties run the model, treat the quality claim as a claim. The price, on the other hand, is a public rate card, and rate cards are falsifiable in the best way: you can go pay it.
What AI Video Generation Costs Per Second in June 2026
To see why Varya's number startled people, line it up against the published per-second prices of the major hosted models at the 720p tier.
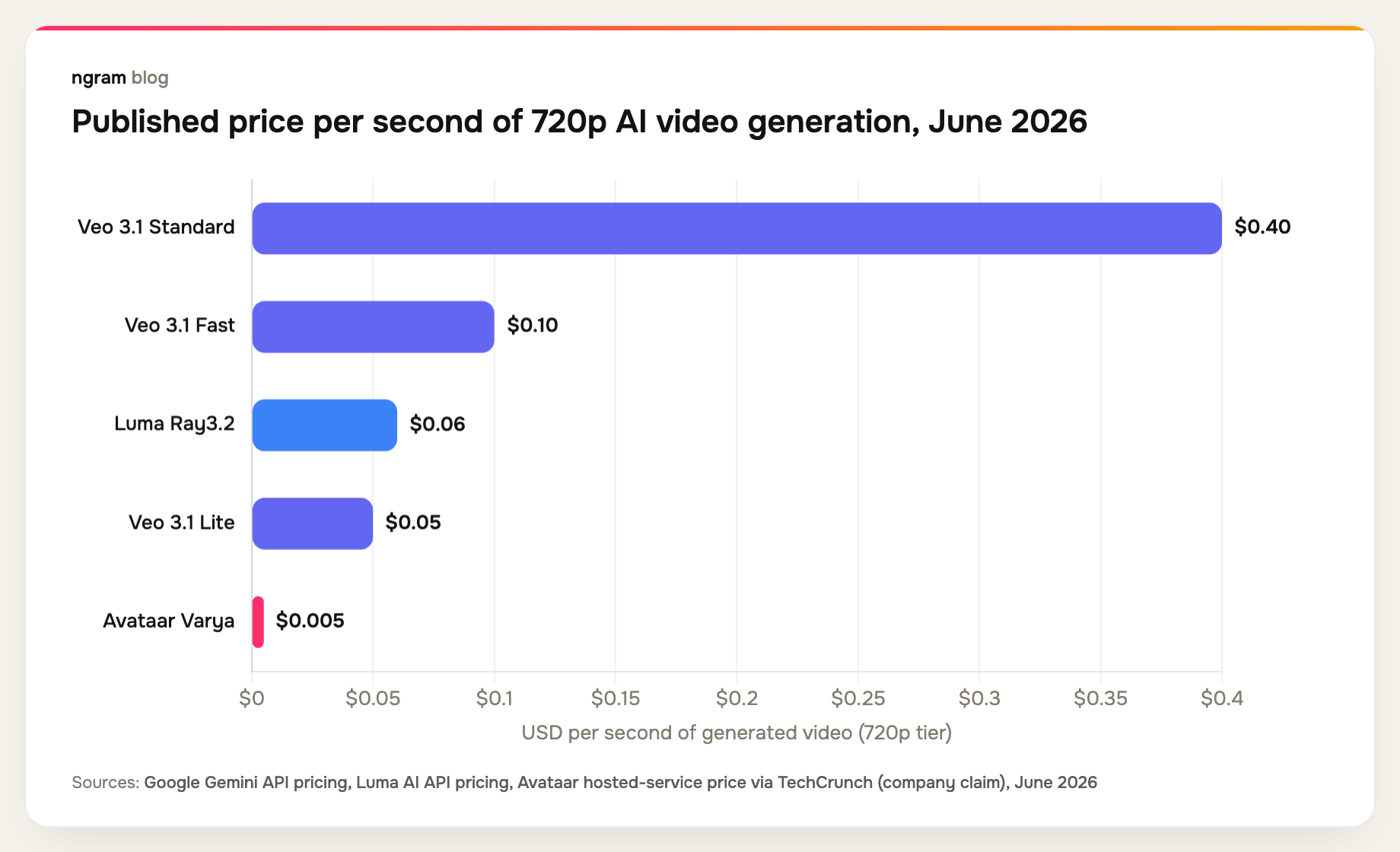
Look at the spread. Google's own Gemini API pricing lists Veo 3.1 at $0.40 per second standard, $0.10 fast, and $0.05 for the Lite tier at 720p. Luma's API pricing works out to $0.06 per second for a 720p Ray3.2 text-to-video clip. So even before Varya, the floor for credible hosted generation had already dropped to a nickel. Varya undercuts that floor by another 10x.
And the floor was already falling fast. On January 26, 2026, Luma launched Ray3.14 with 4x faster generation and per-second pricing 3x cheaper than Ray3, pitched explicitly as eliminating the quality-speed-cost tradeoff. When a frontier lab's flagship announcement is a price cut, the market has told you what it is competing on.
The counter-example proves the same point. OpenAI is shutting down Sora in two stages: the app and sora.com closed on April 26, 2026, and the API, including Sora 2 and Sora 2 Pro endpoints, stops on September 24, 2026, per OpenAI's help center. The Decoder reports OpenAI is redirecting that compute toward coding tools and enterprise customers. In a market where the price of a generated second keeps halving, premium raw generation without a workflow attached turned out to be a hard business.
Distillation Is the Mechanism, Not Magic
Why does cutting 50 steps to 4 cut the price 10x or more? Because diffusion models generate video by denoising, and every denoising step is a full forward pass through the network. GPU seconds scale almost linearly with step count. Cut the steps by 12x and you cut the dominant cost of inference by nearly the same factor.
Distillation gets you there with a teacher-student setup: the full Wan 2.2 model acts as the teacher, and a student model learns to land near the teacher's output in a fraction of the steps. The benchmark Avataar shared with TechCrunch makes the effect concrete. Same H200 GPU, same 5-second 720p clip: 1,230 seconds for the base model, about 45 seconds for Varya.
This is the same playbook behind every "fast" tier on the market. Veo 3.1 Fast costs a quarter of Veo 3.1 Standard. Ray3.14's 4x speedup arrived with its 3x price cut. Step reduction is where most of those gains come from, and it is why the cost curve keeps falling even when the underlying GPUs do not get cheaper.
Distillation is not free, though. Aggressive step reduction has historically traded away fine detail, motion fidelity, and prompt adherence at the margins. Avataar says Varya holds quality at 4 steps. That is exactly the claim its promised technical report and the AI Kosh release will let outsiders test.
The Open-Weight Stack Became the Substrate
Varya's most interesting design decision is the one that got the least coverage: Avataar did not build a foundation model. It built on one. That only works because the open-weight video stack matured fast over the last 18 months.
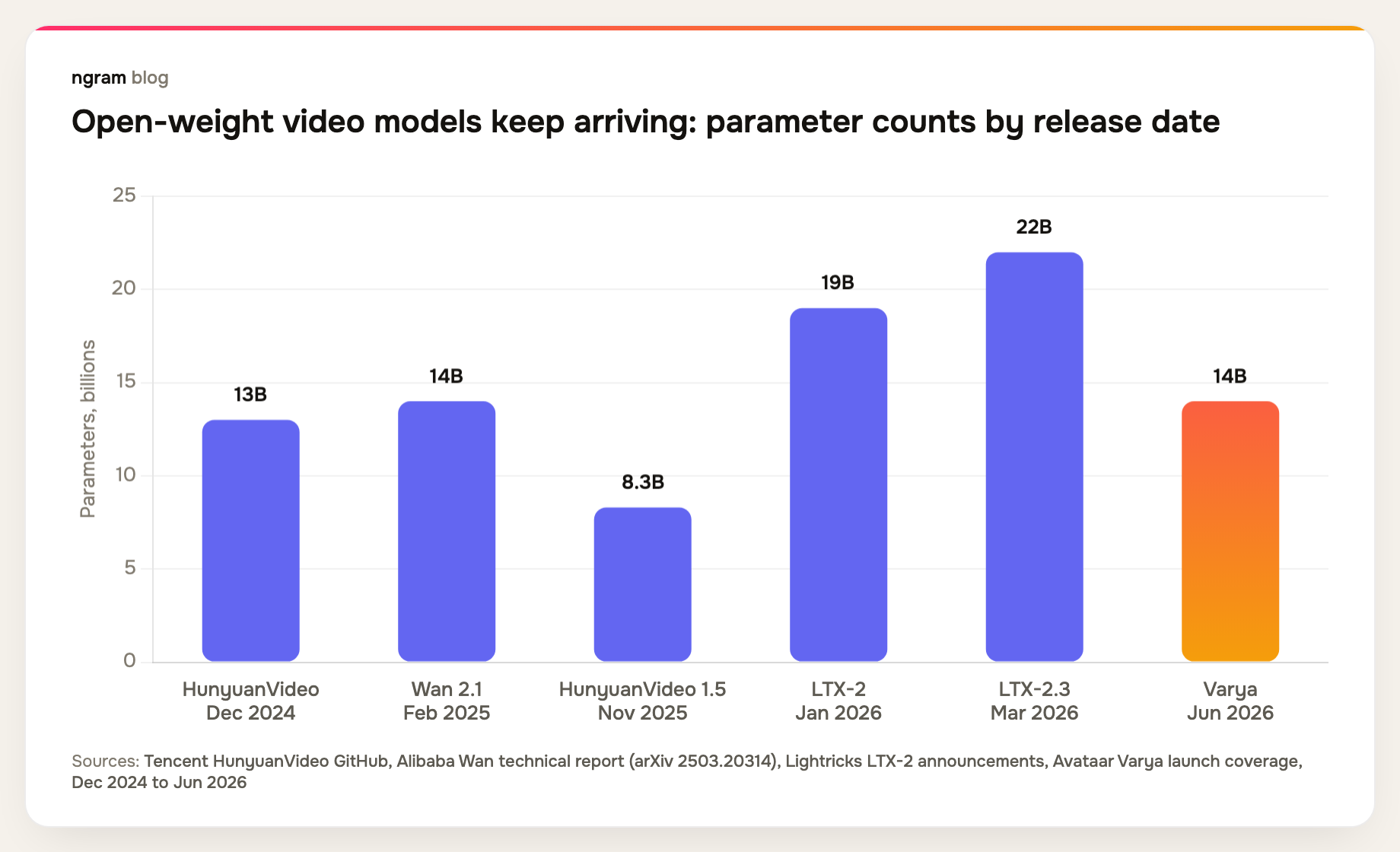
The cadence tells one half of the story. Tencent open-sourced the 13B HunyuanVideo in December 2024. Alibaba released Wan 2.1 under Apache 2.0 in February 2025, then followed with the Mixture-of-Experts Wan 2.2 in July 2025. Lightricks open-sourced LTX-2 in January 2026 with native 4K and synchronized audio, then shipped the 22B LTX-2.3 in March. Varya joins in June 2026 as the first state-program entry in the list.
Quality tells the other half. Open weights stopped being the budget option over a year ago.
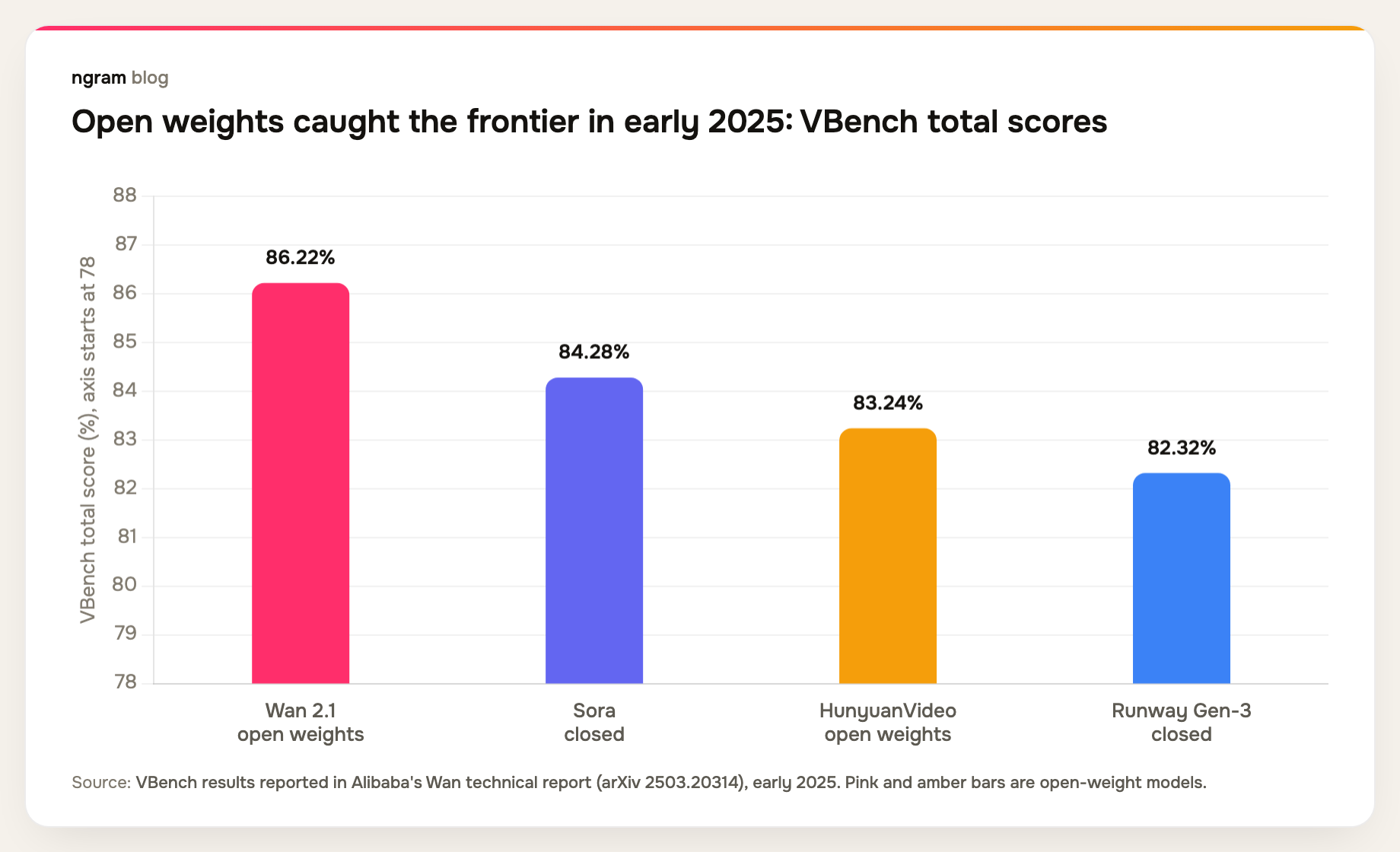
When Alibaba published the Wan technical report in early 2025, the open-weight Wan 2.1 topped VBench at 86.22%, ahead of Sora's 84.28%. Once an Apache-licensed model leads a public benchmark, every team downstream faces a new default question: why train from scratch when you can specialize and distill?
That is the pattern Varya makes explicit. Take an open substrate, specialize it for a market the original builders did not prioritize, distill it until the economics work, and release the result openly so the cycle repeats. The open releases are coming from every layer of the stack now, including chipmakers, as we covered in our NVIDIA Cosmos 3 analysis.
Sovereign AI Programs Now Ship Video Models
Varya is also a data point about who funds this collapse. Avataar is one of roughly 12 startups selected under the IndiaAI Mission, a program TechCrunch sizes at about $1.2 billion, and it received subsidized GPU compute in exchange for releasing the model publicly. That trade, public compute for public weights, is the part other governments will study.
MeitY Secretary S Krishnan framed the launch as deliberate capability building: "Varya represents the kind of research-led capability building that we seek to enable," per Analytics India Magazine. Peak XV's managing director was blunter about the economics in TechCrunch: "Cost is the biggest unlock for AI adoption in India."
The cultural angle is not decoration either. Outlook Business reports Varya was trained to reflect India's regions, festivals, communities, and public spaces, aimed at education, commerce, governance, citizen services, and MSME storytelling. Global models trained mostly on Western data genuinely do miss this context, and a 1.4-billion-person market is a strong reason to fix it at the model layer.
For everyone outside India, the second-order effect matters more. When a state subsidizes an open-weight release, including training data, it anchors the global price floor, because any developer anywhere can self-host the result. Expect more of this: sovereign AI programs in other regions now have a template that costs less than training a frontier model and produces a headline-grade artifact.
Cheap Generation Does Not Make Video Cheap
Here is the practical read for teams that actually ship videos. Raw clip generation is commoditizing. At Varya's claimed rate, a full minute of 720p footage costs about 30 cents. Even at Veo 3.1 Fast prices, it is $6. Two years ago the equivalent line item was a production day.
But a second of footage for half a cent does not decide what the video should say. It does not write the script, plan the scenes, hold your brand, place the captions, or produce the five channel formats your launch actually needs. As generation gets cheap, those jobs become the cost. The same shift happened when an AI video generator stopped being a novelty and became a line item: the model is the engine, and the workflow around it is the vehicle.
You can see it in the adoption data too. Cost has been falling off the list of blockers for years, while skills and production workflow stay stubbornly at the top, a pattern visible across our AI video statistics roundup. Cheaper seconds amplify that imbalance: more teams can afford generation, so more teams hit the planning and editing wall.
That premise is why we built ngram the way we did. ngram turns a prompt, URL, PDF, deck, or screen recording into a finished video on top of frontier models, with the script, storyboard, brand, and captions handled in one text to video workflow. When base generation gets 10x cheaper, that saving flows straight through to the finished video instead of getting trapped at the clip stage. If your team ships video every week, try ngram and price the whole workflow, not the second.
What to Watch Next
- The AI Kosh release. Open weights plus training data is a stronger commitment than most labs make. Whether both actually land, and under what license, decides how much of the launch survives contact with developers.
- Third-party benchmarks. The 4-step quality-parity claim against Wan 2.2 and the cost comparison against Veo-class models both need outside numbers, starting with the promised technical report.
- Price responses. Google already has a $0.05 tier and Luma already cut 3x in January. If either moves again before year end, the collapse thesis stops needing an argument.
- More sovereign entries. The IndiaAI Mission selected about 12 startups. Varya is the first video model out of that pipeline, and other national programs are watching the subsidized-compute-for-open-weights trade.
- September 24, 2026. When the Sora API shuts off, its workloads have to land somewhere, and the receiving models will mostly be cheaper than what they replace.
Frequently Asked Questions
What is Avataar's Varya?
Varya is a 14-billion-parameter AI video generation model launched by Bengaluru-based Avataar.ai on June 12, 2026, under India's IndiaAI Mission. It was built by distilling Alibaba's open Wan 2.2 model and generates video from text prompts or images, with training tuned to Indian cultural context.
How much does Varya cost per second of video?
Avataar prices Varya at Rs 0.48 per second of generated video on its hosted service, about $0.005. TechCrunch contrasts that with Veo, Kling, Luma, and Runway, which typically charge $0.10 or more per second, a roughly 20x difference. Avataar's own benchmarks frame it as up to 10x more cost-efficient than leading global models.
Is Varya open source?
Avataar plans to release Varya as an open-weight model on AI Kosh, the Indian government's public AI repository, along with its training data, so developers can self-host or modify it. As of the June 12, 2026 launch, the weights were announced but not yet published, so check AI Kosh for the actual release and license terms.
What is distillation in AI video generation?
Distillation trains a smaller or faster student model to reproduce the output of a larger teacher model. For diffusion-based video models, the main win is step reduction: Varya generates in 4 denoising steps instead of Wan 2.2's 50, which cuts GPU time per clip by roughly the same factor and is the core of its cost advantage.
Why is the cost of AI video generation falling so fast?
Three forces stack. Open-weight models like HunyuanVideo, Wan, and LTX-2 give anyone a frontier-adjacent starting point. Distillation and step reduction cut the inference compute per clip by 10x or more. And competition plus state subsidy, like the IndiaAI Mission's compute support for Varya, keep pushing published prices down, from $0.40 per second at the top of Google's Veo 3.1 range to half a cent on Varya's rate card.
Does cheaper AI video generation mean finished videos get cheaper too?
Partly. The raw footage line item shrinks dramatically: a minute of 720p generation costs about 30 cents at Varya's claimed rate. But scripting, scene planning, brand consistency, captions, and channel formats still take time and judgment, so the bottleneck moves up the workflow. Teams that pair a cheap text to video generator with a strong production process capture the full saving; teams that only buy cheap clips usually do not.