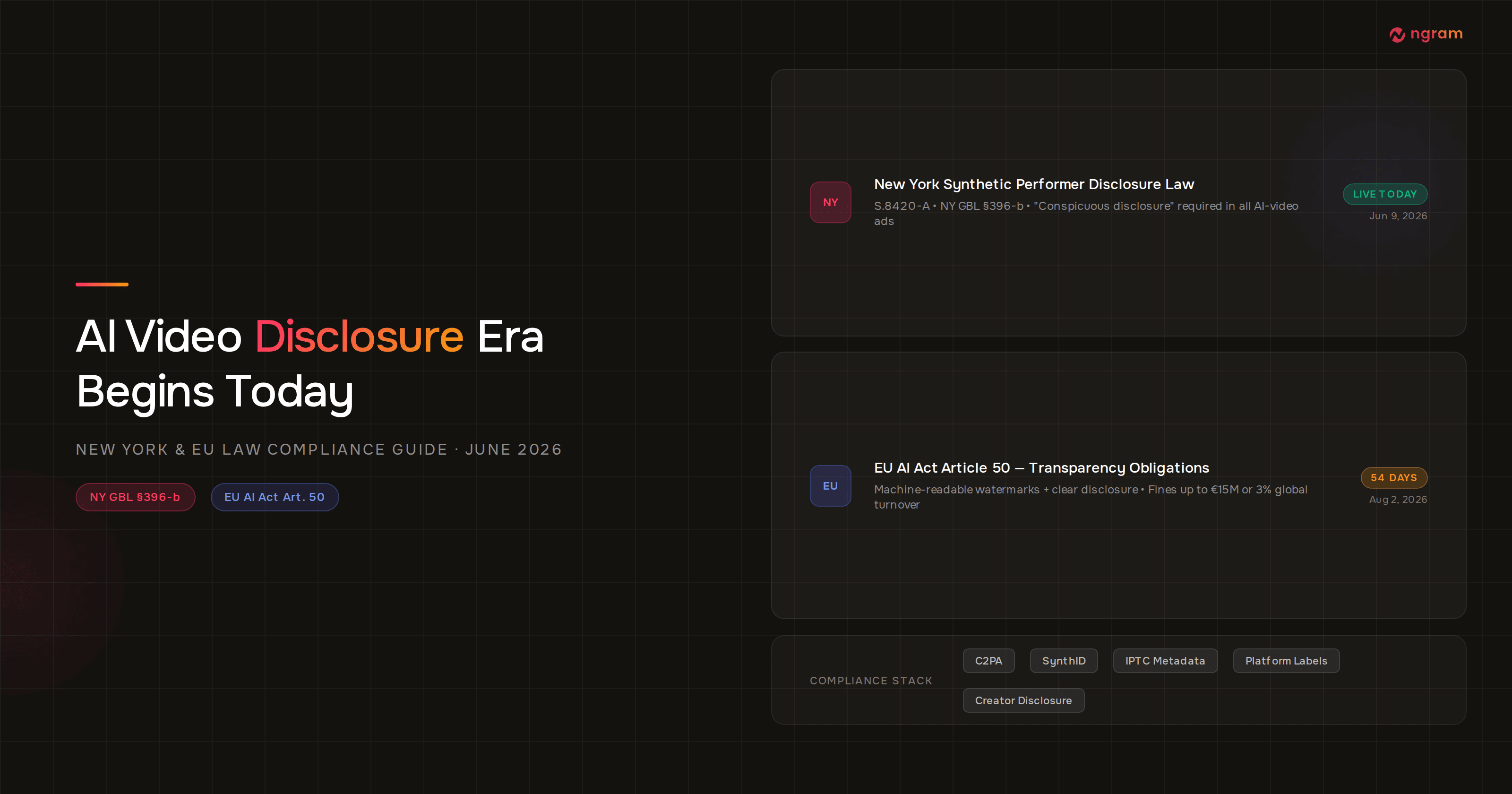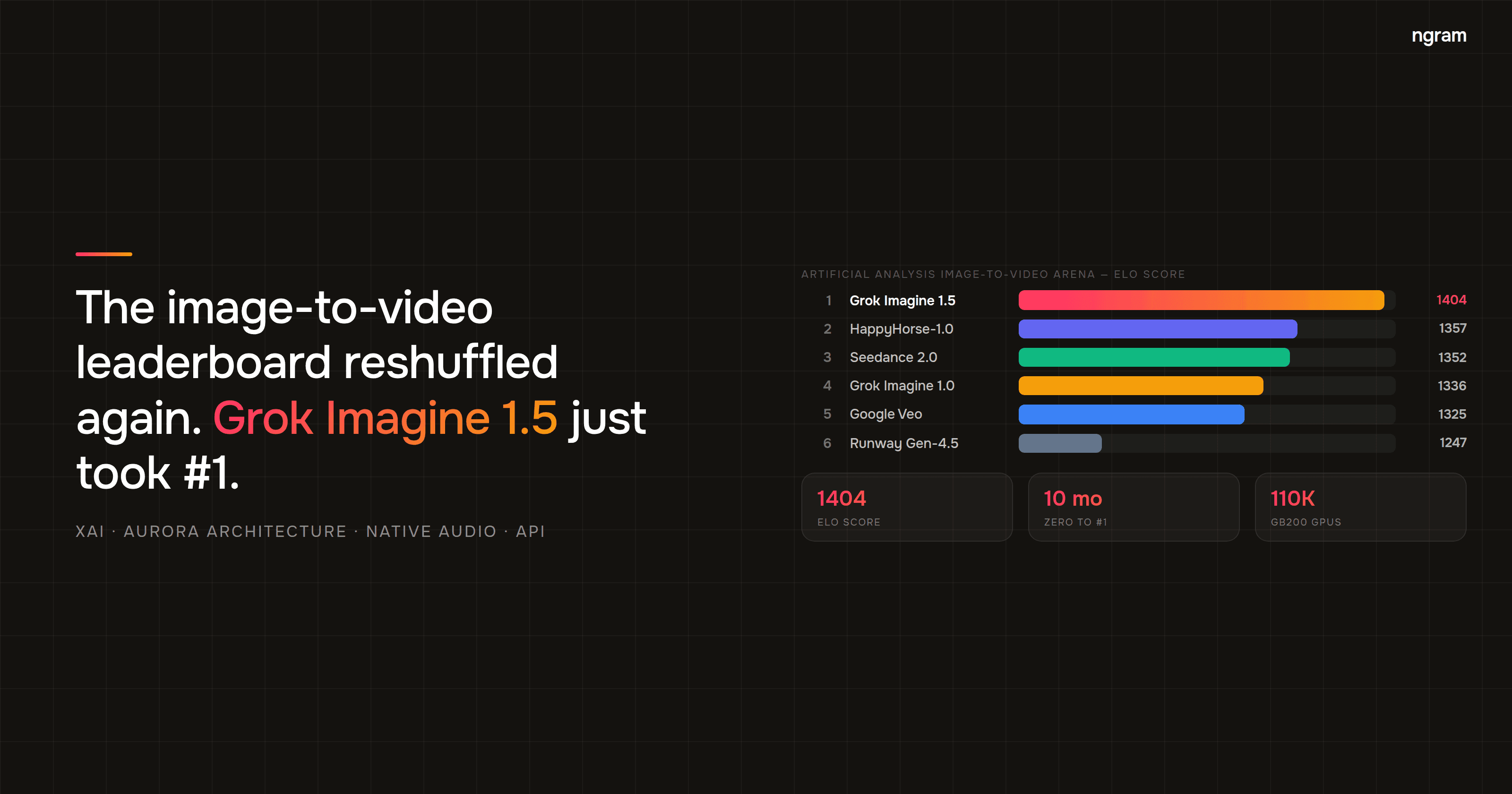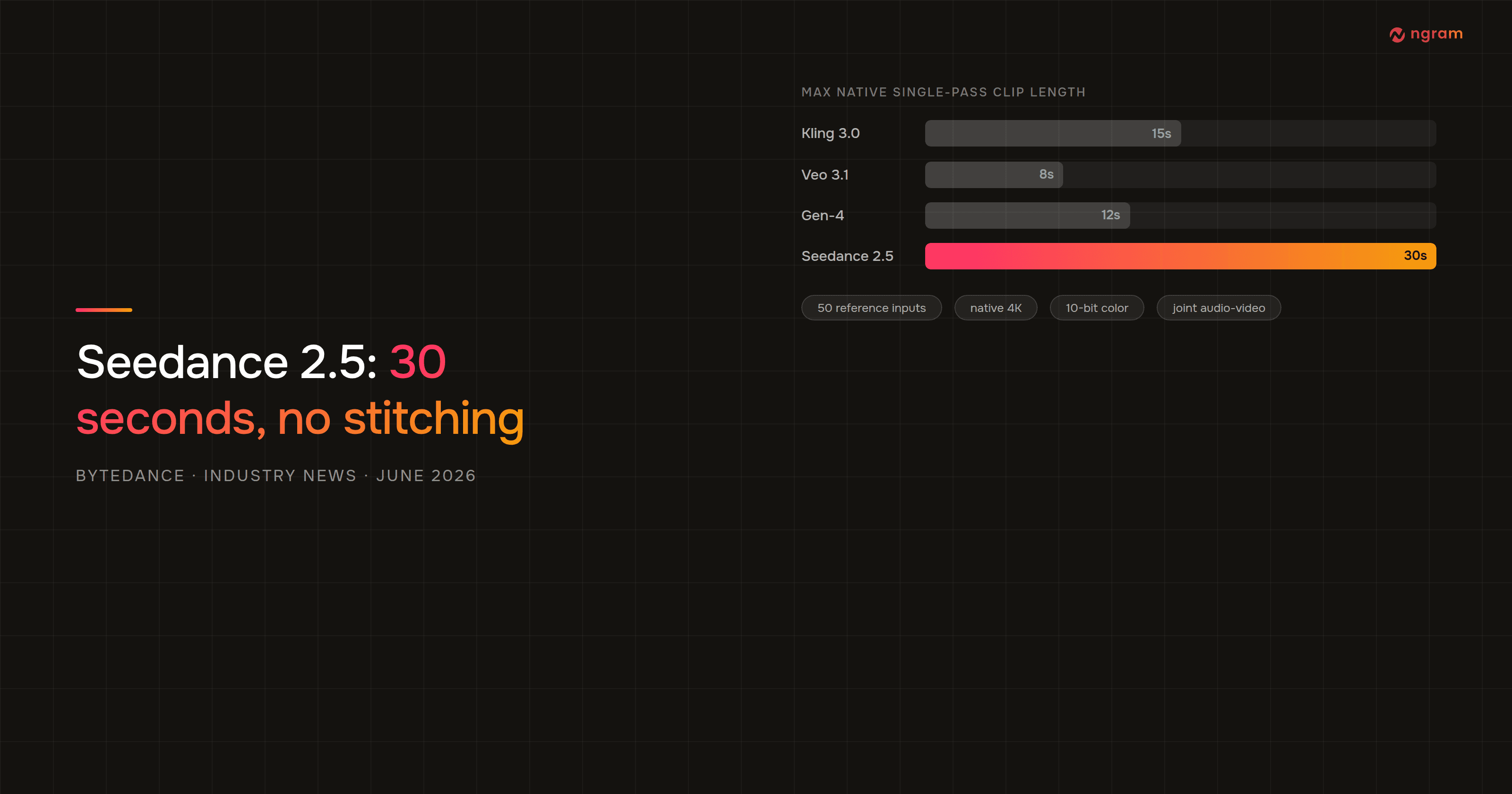
On June 23, 2026, ByteDance took the stage at its annual Volcano Engine FORCE Conference in Beijing and announced Seedance 2.5 - the first major AI video model to generate a native 30-second clip at 4K resolution in a single pass. No stitching. No seams. No consistency breaks between shots.
That specific claim matters more than it sounds. The 8-15 second generation ceiling on today's leading models isn't a minor inconvenience for production teams - it's the reason AI video still requires significant manual cleanup before it's usable. Seedance 2.5 appears to clear that ceiling. Here's a technical breakdown of what was announced, what it means for AI video production workflows, and what hasn't been confirmed yet.
The Stitching Problem: Why 30 Seconds Matters
To understand why native 30-second generation is significant, you need to understand what production teams deal with today. Most leading AI video models - Google Veo 3.1, Runway Gen-4, Kling 3.0 - cap single-pass generation at somewhere between 8 and 15 seconds of usable footage. For anything longer, you stitch multiple generations together.
Stitching sounds straightforward on paper. In practice, it is one of the main reasons AI video production stays slower and more expensive than it should be. Each generation is stateless - the model doesn't remember what it just created. By the time you're on your fourth or fifth clip, character appearance has shifted subtly, lighting has changed tone, and motion style has drifted from the opening shot. The more clips you stitch, the more manual correction each join requires.
For a 30-second ad spot, that means a minimum of two to four generation passes just to cover the runtime, plus cleanup work at every seam. For a 60-second piece, you might be looking at five or six generations. The time overhead is real, and the consistency overhead is worse.
Seedance 2.5 solves this at the generation layer. A single 30-second clip runs through one forward pass, so the model holds character appearance, lighting, and motion physics across the full duration. No joins to smooth over. No drift to correct.
The chart below shows the current native clip-length ceiling for each major model, based on published documentation as of June 2026.
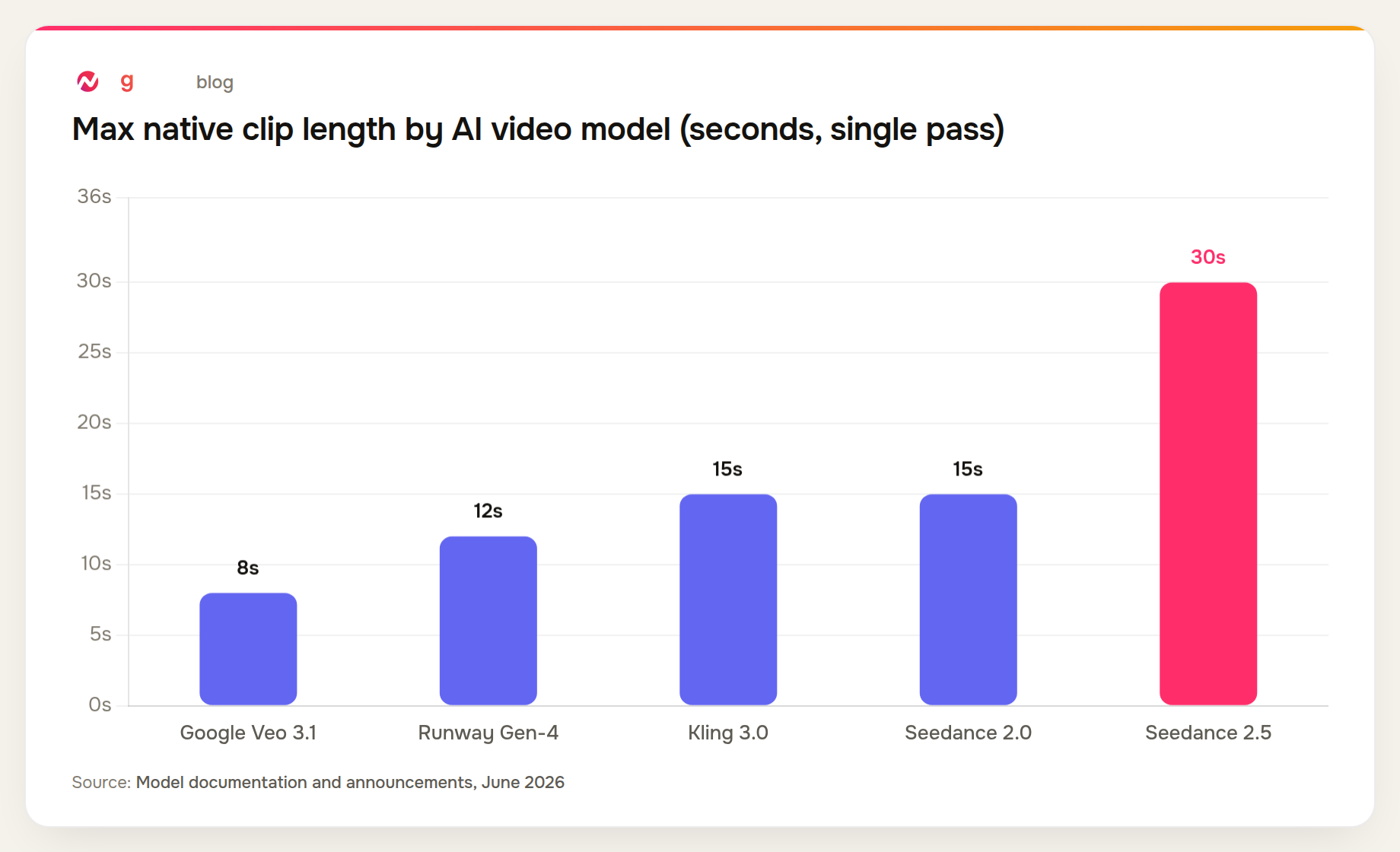
The gap is large enough that it reshapes what AI video can cover in a single generation. A 30-second native clip covers the full runtime of a standard social ad unit, a typical product teaser, or a complete onboarding video segment without a single join.
What ByteDance Actually Announced
Seedance 2.5 was announced on stage at the Volcano Engine FORCE Conference on June 23, 2026, by Volcano Engine president Tan Dai. ByteDance demonstrated the model live but was clear that this was an enterprise beta announcement, not a general release. Public availability is targeted for early July 2026 via the Volcano Engine platform.
The key specifications ByteDance confirmed:
- 30-second native clip generation in a single pass at native 4K resolution
- Up to 50 simultaneous multimodal reference inputs - images, audio clips, 3D models, and style references - up from 12 in Seedance 2.0
- 20% improvement in prompt adherence versus Seedance 2.0
- 10-bit color depth for smoother gradients and greater post-production flexibility
- Unified joint audio-video generation - visual and audio signals co-processed in the same latent space rather than generated separately and synchronized after
- 3D white-box preview for low-fidelity animation testing before committing to a full render
- Region-level editing - change a background, swap a product, or replace a subject without affecting the original motion, camera, or lighting
The conference also included announcements for Seedream 5.0 (image model), Seed-Audio 1.0 (audio generation), and Doubao seed2.1 (a language model ByteDance positioned against Claude Opus 4.6 for coding and agent tasks). The video and audio announcements are the most immediately relevant for production workflows.
The Architecture Behind Consistent 30-Second Clips
ByteDance describes the system that holds consistency across a full 30-second clip as an optimized spatial-temporal attention mechanism. The model attends across the entire clip duration during generation rather than producing frames in short segments. That is what prevents the drift problem: character appearance, lighting, and motion physics are constrained across the full temporal window, not just across a 10-second span.
The unified joint audio-video generation is also worth unpacking. In most video generation pipelines today, audio is produced separately - either via a dedicated audio model that receives the video as input, or by running a voice generation model in parallel and syncing after. The problem is that sync is always approximate. Ambient sound doesn't match what's happening visually in the way that a truly co-generated system would. Seedance 2.5 co-processes visual and audio signals in the same latent space, which ByteDance says produces native synchronization between on-screen actions and their corresponding sound effects.
The 3D white-box preview is an interesting addition for production efficiency. Before committing to a full 4K render - which takes time and credits - teams can run a low-fidelity version to check camera blocking, character positioning, and scene composition. Catching problems at this stage rather than after a full generation is a meaningful workflow improvement for anyone running multiple iterations.
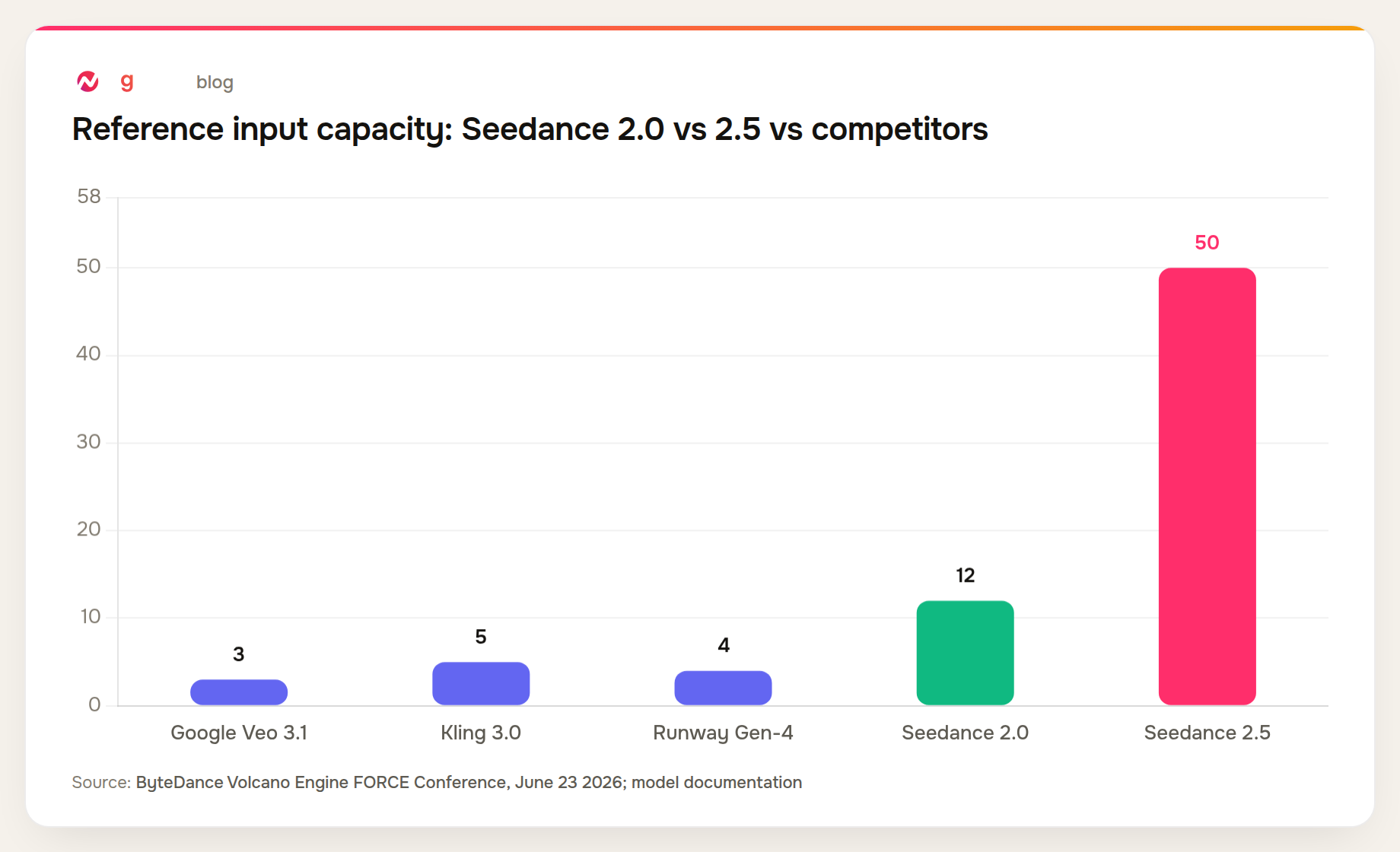
50 Reference Inputs: Why That Number Is Significant
The jump from 12 to 50 simultaneous reference inputs isn't just a spec bump. It changes what brand consistency and character consistency actually look like at generation time.
At 12 inputs, you can feed the model a character sheet, a product shot, and a handful of style references before the budget fills. At 50, a brand team can simultaneously supply a full product shoot, multiple character references for different angles, the brand's motion style examples, environmental references, audio tone samples, and a 3D model of the product - all within a single generation. The model holds all of those constraints simultaneously.
Google Veo 3.1, for comparison, accepts approximately 3 reference inputs per generation. The gap in reference capacity is what separates consumer-grade AI video from something production teams can use for high-consistency brand content.
The chart below shows reference input capacity across the main models as of June 2026.
The region-level editing feature compounds this. Once a master clip is generated with the full reference set, teams can swap specific elements - a product variant, a background locale, a seasonal overlay - without re-running the full generation. For high-SKU consumer brands or teams localizing content across markets, that workflow is substantially faster than what exists today.
Where Seedance 2.0 Already Stands
Seedance 2.5 isn't public yet, so any comparison to existing models has to start with Seedance 2.0 - the current version available through Volcano Engine's API, Dreamina, Doubao, and CapCut.
According to the Artificial Analysis blind-preference leaderboard, Seedance 2.0 currently leads the text-to-video arena at Elo 1,219, ahead of Kling 3.0 Pro (1,105) and Google Veo 3.1 (1,094). It also holds the top position in the image-to-video leaderboard. These rankings reflect user preference on a sampled set of prompts - not guaranteed performance across all use cases - but they establish Seedance 2.0 as the current quality benchmark.
On pricing, Seedance 2.0 runs at approximately $9 per minute of 1080p output, compared to roughly $20/minute for Kling 3.0 Pro and $24/minute for Google Veo 3.1. Seedance 2.5 pricing has not been confirmed.
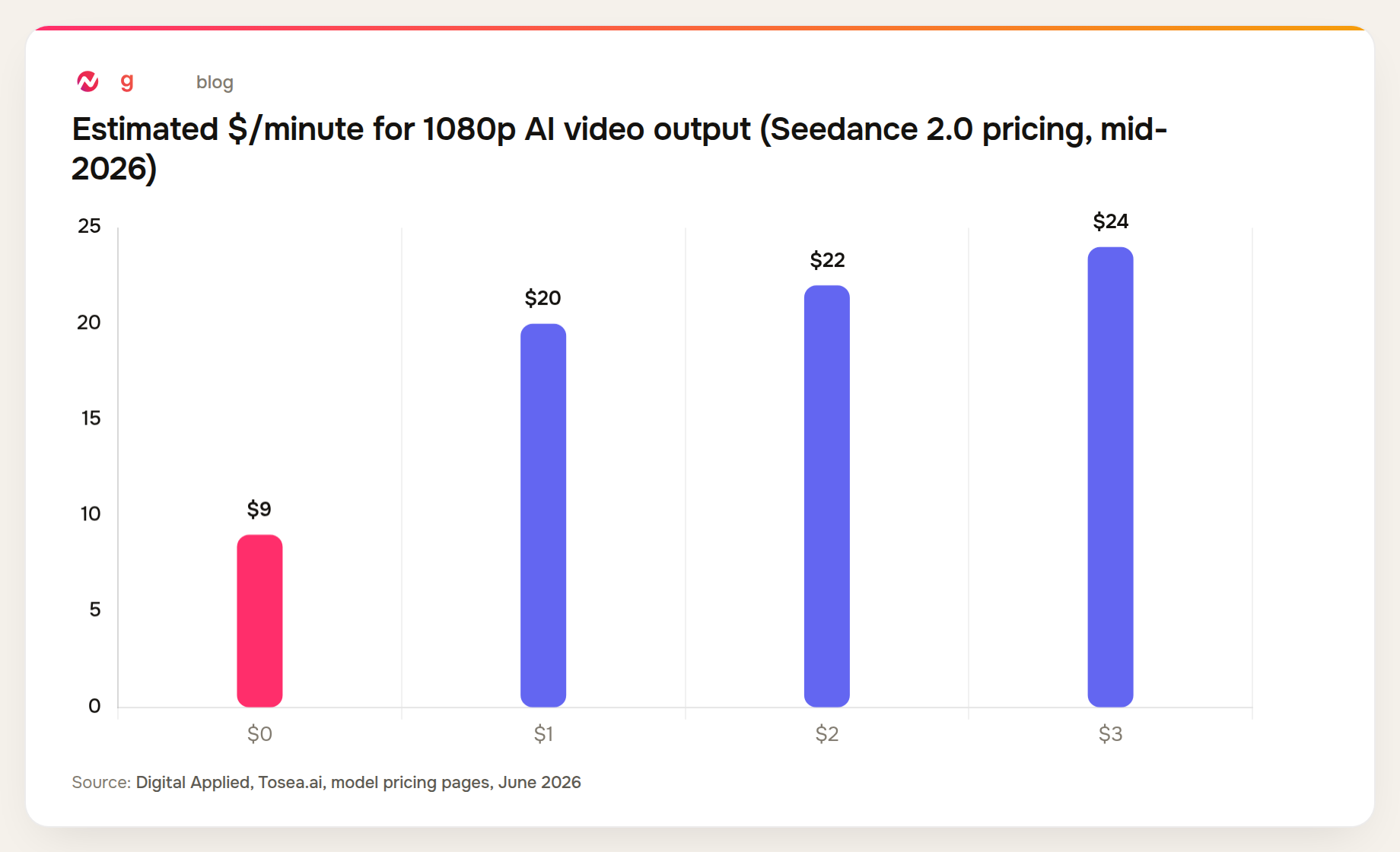
The combination of leaderboard-leading quality and below-market pricing is why Seedance 2.0 has already gained traction in production workflows, particularly for teams generating high volumes of short-form video content. Seedance 2.5's extended native length makes that combination apply to longer-form content as well.
The IP and Compliance Context
This announcement comes with regulatory context that matters for enterprise adoption. In March 2026, the Motion Picture Association sent ByteDance a cease-and-desist following concerns about Seedance 2.0's training data and output. ByteDance subsequently added watermarking, IP guardrails, and face detection filters to the model. Those protections carry forward into Seedance 2.5.
ByteDance has not announced a settlement with Hollywood. The C&D is still active. For enterprise buyers who need documented IP provenance before signing off on AI-generated content, that gap in the compliance record is worth tracking before the public launch in July.
ByteDance CEO Liang Rubo framed the company's AI investment at the conference as existential: "climbing the AI summit is the company's top priority." ByteDance simultaneously claimed approximately 49.5% of China's public-cloud large-model market share and 180 trillion tokens processed daily across its products. Seedance 2.5 also distributes through CapCut, which has 400 million monthly active users - a distribution advantage that no other foundation video model currently matches.
What This Means for the AI Video Production Stack
Seedance 2.5 is a foundation model - it isn't a finished product for end users. Its impact on AI video creation shows up in the tools and platforms built on top of it.
When a foundation model can hold 30 seconds of native consistency, any tool that generates scenes from that model gets longer, cleaner clips to work with. For platforms that orchestrate multiple scenes into finished multi-scene videos, a stronger underlying model means fewer generation attempts per scene and less correction work between clips. The stitching problem at the foundation layer doesn't disappear entirely in orchestration tools - you're still joining distinct generations together - but when each generation starts cleaner and holds consistency longer, the seams are narrower and easier to manage.
For content teams using tools like ngram that generate B-roll and scene fills from text prompts and other inputs, improvements at the foundation model layer translate directly into higher-quality scene clips - longer takes with more consistent lighting, character appearance, and motion that require less manual adjustment before they fit into a finished video.
The use cases that benefit most from 30-second native generation are the ones that map naturally to standard content units:
- 30-second ad spots at 4K with brand consistency - the most common social ad format, now coverable in a single generation
- Product demo videos - complete hero shots without seam correction between cuts
- E-commerce product variants - generate one master clip, use region editing to swap product details for each SKU without a full re-generation
- Animated drama and narrative sequences - enough continuous runtime to build coherent multi-beat scenes
What Isn't Confirmed Yet
Seedance 2.5 was demonstrated on stage, not shipped publicly. Before reading too much into the announcement, a few things are worth flagging:
No independent benchmarks exist for Seedance 2.5. The Artificial Analysis Elo scores cited above are for Seedance 2.0. Any 2.5 arena scores circulating before the July launch should be treated as unverified. The 30-second and 4K claims are demonstration-based - confirmed by multiple journalists present at the conference, but not yet independently tested at scale across diverse prompts.
Pricing for Seedance 2.5 hasn't been announced. The cost advantage that makes Seedance 2.0 attractive to high-volume production teams may or may not carry over. Native 30-second generation at 4K is computationally more expensive than 15-second generation, so some pricing premium is plausible.
The Hollywood IP situation is unresolved. ByteDance added compliance tooling after the March 2026 C&D, but no settlement has been announced. Enterprise buyers in markets sensitive to copyright provenance will want to wait for clarity before building production workflows on Seedance 2.5.
Finally, regional availability outside China hasn't been specified. ByteDance's stated target is "global enterprise beta" at launch, but access restrictions similar to those that affected Seedance 2.0's international rollout remain possible.
The Bigger Picture: Two Years of AI Video Compression
Seedance 2.5 arrives in a market that's changed fast. OpenAI shut down Sora in March 2026 - reportedly losing approximately $1 million per day in operational costs. Seedance 2.0 itself was frozen globally in March 2026 following the Hollywood C&D. Alibaba launched HappyHorse 1.1 on June 22, the day before this announcement, into the gap created by those exits.
Within roughly 18 months, the AI video model landscape has gone from a handful of research demos to a competitive market where quality, native clip length, reference input capacity, and cost per minute are all moving fast. Seedance 2.5 sets a new ceiling on two of those dimensions simultaneously - native length and reference capacity - while keeping the quality baseline that Seedance 2.0 already established at the top of the leaderboard.
Whether that ceiling holds when the model ships publicly in July and gets tested across the full range of production use cases is what matters next. Until then, the announcement is meaningful but the results are demonstration-level. Watch for independent benchmark results from the Artificial Analysis arena when Seedance 2.5 goes live.
Frequently Asked Questions
What is Seedance 2.5?
Seedance 2.5 is ByteDance's latest AI video generation model, announced June 23, 2026 at the Volcano Engine FORCE Conference in Beijing. It generates up to 30 seconds of native video in a single pass at 4K resolution, doubling the prior generation ceiling for major AI video models. It is currently in enterprise beta with a public launch targeted for early July 2026.
How does Seedance 2.5 compare to Kling 3.0 and Veo 3.1?
On native clip length, Seedance 2.5 significantly outpaces both: Kling 3.0 caps at 15 seconds per generation and Google Veo 3.1 at roughly 8 seconds. On reference inputs, Seedance 2.5 accepts 50 versus Kling 3.0's 5 and Veo 3.1's approximate 3. Note that these comparisons are against the Seedance 2.5 announced specification, not independently verified benchmarks. The Seedance 2.0 quality benchmark (Elo 1,219 on Artificial Analysis) already places it above both Kling 3.0 Pro and Veo 3.1 in blind preference testing.
When will Seedance 2.5 be publicly available?
ByteDance has stated a public launch target of early July 2026 via the Volcano Engine platform. Enterprise beta access was live at the time of announcement on June 23. There is no confirmed US-specific release date.
What is the stitching problem in AI video generation?
The stitching problem refers to the consistency degradation that happens when production teams concatenate multiple short AI-generated clips to create longer videos. Because each generation pass is stateless - the model doesn't remember previous clips - character appearance, lighting, and motion style drift between clips. By the fourth or fifth clip in a sequence, the drift is often visible enough to require manual correction at each join. Seedance 2.5 addresses this by generating a full 30-second clip in one pass, maintaining consistency across the entire duration without any joins.
What were the copyright issues with Seedance 2.0?
In March 2026, the Motion Picture Association sent ByteDance a cease-and-desist related to concerns about Seedance 2.0's training data and output. ByteDance subsequently froze global distribution of Seedance 2.0 outside of China and added watermarking, IP guardrails, and face detection filters to the model. Those compliance measures carry forward into Seedance 2.5, but no settlement between ByteDance and Hollywood studios has been publicly announced as of the June 23 launch.
How does joint audio-video generation in Seedance 2.5 differ from other models?
Most AI video models handle audio and video as separate generation steps - they produce the video first, then run a separate audio model to generate matching sound, and sync the two outputs. Seedance 2.5 co-processes visual and audio signals in the same latent space during generation. According to ByteDance, this produces native synchronization between on-screen actions and their corresponding sound effects, rather than an approximate sync that's applied after the fact.
Does AI video generation still need human review before use in production?
Yes. Even with longer native clip length and improved consistency, AI-generated video requires human review before production use. Specific risks include unintended content in the generated clip, inconsistencies that weren't apparent in the 3D preview, and output that technically meets the prompt but doesn't match the intended message. The 3D white-box preview in Seedance 2.5 reduces but doesn't eliminate revision cycles. Most production teams using AI video as part of a larger workflow, including those using tools like ngram to turn content into structured multi-scene videos, treat AI generation as a starting point that requires editorial judgment before final use.